
Uno de los principales campos de la Inteligencia Artificial (IA) es el Procesamiento de Lenguaje Natural (PLN). Al igual que otras subdisciplinas del área, como la Visión Artificial, el Aprendizaje Automático o el Aprendizaje Profundo, en los últimos años ha tenido un crecimiento exponencial: más datos disponibles, mayor capacidad de cómputo y nuevas técnicas se retroalimentan de forma continua, llevando el estado del arte a nuevos territorios.
Por “lenguaje natural” se entiende a la lengua hablada o escrita por humanos para comunicarse. A diferencia de los lenguajes formales, como podría ser un lenguaje de programación, el lenguaje natural está en continuo cambio: adquiere léxicos, a veces nuevas formas gramaticales y está poblado de ambigüedades, entre otros rasgos de su perpetuo estado de transformación. En consecuencia, las computadoras se llevan bien con los lenguajes formales pero no con los naturales. Para las máquinas, entre otras dificultades, es particularmente complicado manejar la ambigüedad del lenguaje natural, ya sea de tipo fonética, morfológica, sintáctica, semántica o pragmática. El PLN vino para ayudar a que las computadoras entiendan el lenguaje natural.
Hablamos de PLN en aplicaciones como los chatbots (cualquiera de nosotros los ha sufrido al hacer alguna consulta o reclamo web), los teclados predictivos (facilitadores y a veces irritantes), los correctores ortográficos de los editores de texto o Google Translate (deidad del panteón googleano). Dentro del Procesamiento del Lenguaje Natural, se distinguen distintas sub-áreas o especialidades, ya sea la traducción automática, el análisis de sentimiento (por ejemplo, clasificar la reseña de una película como positiva o negativa, o si un tweet tiene “discurso de odio”) o los modelos de lenguaje (ML), que serán mi objeto de interés de aquí en más.
Los modelos de lenguaje
Un ML es un modelo matemático-estadístico implementado computacionalmente, o sea escrito en algún lenguaje de programación (hoy el lenguaje estrella de la IA es Python), que corre sobre una o un conjunto de computadoras. ¿Qué hace un ML? Puede hacer muchas cosas, pero me voy a centrar en los que generan texto, ya sea palabra a palabra o carácter a carácter. ¿Pero cómo un ML, un modelo “matemático-estadístico implementado computacionalmente” llega a generar texto? Pues al modelo se le entrena con texto para que aprenda (ahora tal vez vaya tomando sentido lo de inteligencia artificial). ¿Y qué sería en este caso aprender? El modelo aprende de los datos, que además deben ser muchos (muchísimos) y de calidad. De ser pocos o malos, la mayoría de los modelos no alcanzarían buenos resultados.
Los ML markovianos, como los N-gramas, tratan de predecir la próxima palabra a partir de las N-1 anteriores. Son probabilísticos, y para su sencillez, obtienen resultados aceptables. Un ejemplo divertido de ML basado en cadenas de Markov es el de la cuenta de Twitter @comentarista_uy . Se entrenó un modelo con miles de comentarios dejados por lectores en foros de la página web de El País y cada hora se genera un tweet que es publicado en la cuenta. Con una rápida inspección, podrán ver cómo el modelo logra captar los rasgos más terroríficos —y a veces muy divertidos— de los foristas. El modelo es sencillo y a veces tiene fallas semánticas y sintácticas (entre otras), pero eso lo hace más entretenido, una característica si se quiere buscada.
Estos modelos relativamente sencillos fueron dejando lugar cada vez más a los modelos basados en redes neuronales (RN), modelos computacionales que consisten en una red de neuronas artificiales capaces de aprender juntas. Aprenden, en general, para lograr clasificar objetos, como por ejemplo saber si lo que está en una foto es un perro o un gato. Las RN, aunque aún no se sabe muy bien por qué, son particularmente buenas aprendiendo representaciones. Logran aprender de manera efectiva a detectar patrones, formas, relaciones.
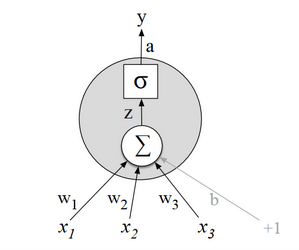

A partir de 2010 aproximadamente, los ML fueron dando lugar cada vez más a las redes neuronales, en especial las Redes Neuronales Recurrentes (RNN por sus siglas en inglés). Algunas de estas redes, como las LSTM (Long Short Term Memory) capturan mejor las dependencias temporales de largo plazo en un texto, enriqueciendo el modelo al tener más en cuenta el contexto de las palabras y oraciones. Una de estas RNN, implementada como ML, y no demasiado compleja, puede ser entrenada y luego puesta a generar texto.
Para una tarea de una de las materias que cursé en Facultad de Ingeniería (Aprendizaje Automático), entrené una de estas redes (ML) con la novela Maluco: la novela de los descubridores (1989), del uruguayo Napoléon Baccino Ponce de León. La historia se desarrolla durante la expedición de Magallanes, por lo que está escrita en un español arcaico cargado de léxico marinero. A pesar de las dificultades, el modelo aprendía a abrir y cerrar las preguntas con signo de interrogación, comenzar diálogos con guión largo, poner mayúsculas en los nombres y agregar signos de puntuación —mejor que algunos humanos, como quien escribe, a decir verdad. El texto generado no era semántica ni sintácticamente perfecto, pero tenía su grado de verosimilitud (la poesía tiene un poco más de gracia con estos experimentos). El modelo también cometía errores y alucinaba palabras inexistentes, algunas de ellas hasta bellas. Ejemplo de salida (el modelo generaba carácter a carácter):
El cara que la lluvia todos eran burlándose de todo el mis graciosos curiosos y engordar sus casas para cuando niega con los muertos que tienen sus gargantas, resolve del hombro. Un poco de miedo, empezado el sol. El anota hay un cerro de medocido. En la nieve, la nave se preocupa lo…
No parece un gran resultado, pero el modelo era sencillo, el texto para entrenarlo no tan extenso y en español (idioma que agrega mayores dificultades que el inglés) y fue hecho por un estudiante con una computadora doméstica. El estado del arte en la materia es otra cosa.
El PLN es un campo en constante estado de cambio y las redes neuronales recurrentes han dejado lugar a ML más sofisticados, como los transformers, también basados en redes neuronales, pero de arquitecturas más complejas. Se trata de modelos en algunos casos con miles de millones de parámetros que fueron entrenados con cantidades descomunales de texto y corren en supercomputadoras. No es de extrañar que hayan salido de las entrañas de empresas como Google, quienes cuentan con buena parte de los datos y el cómputo del globo. Recientemente, el transformer GTP-3 de OpenAI escribió una columna de opinión para el periódico británico The Guardian.
Tal vez no estemos a mucho de que un ML avanzado sea capaz de escribir una novela. Por ahora aprenden bien la gramática, la sintaxis y la semántica, pero no los hilos narrativos. ¿Será cuestión de esperar nuevos avances en el área, modelos capaces de aprender tramas narrativas, mayor cantidad de datos y de cómputo? De todas formas, llegado el momento, la gran pregunta, que podría llenar ríos de tinta, sería: ¿resultaría interesante leer una obra de ficción escrita por una IA? ¿Tendría subjetividad? ¿O sería un nuevo tipo de subjetividad, la sumatoria de las millones de subjetividades de las obras con las que fue entrenado el modelo? ¿Querría el lector consumir este tipo de literatura más allá de una curiosidad morbosa inicial? ¿No es el escritor, en teoría, un gran lector, un poco la suma de las subjetividades de todos a quienes leyó?
Apuesto a que serían preguntas que apasionarían a Borges, de quien sobre este nuevo campo literario imagino frases del ingenio y la acidez que lo caracterizaban. Un gran modelo matemático-estadístico-computacional capaz de engullir bibliotecas enteras, las bibliotecas del mundo, todo lo escrito por la humanidad, para escupir una novela o, más del gusto de Borges, un cuento, o un poema. O tal vez el argentino odiaría todo el fenómeno. No lo sabemos. Lo que es seguro es que no permanecería indiferente.
Inteligencia Artificial y literatura
Pierre Menard es un oscuro escritor francés de magra producción literaria y ensayística, más conocido por haber escrito una réplica exacta de los “capítulos IX y XXXVIII de la primera parte del Don Quijote y de un fragmento del capítulo XXII”. Menard, se nos dice
No quería componer otro Quijote —lo cual es fácil— sino el Quijote. Inútil agregar que no encaró nunca una transcripción mecánica del original; no se proponía copiarlo. Su admirable ambición era producir unas páginas que coincidieran —palabra por palabra y línea por línea— con las de Miguel de Cervantes.
Sobre esa trama se teje el cuento “Pierre Menard, autor del Quijote” (1939), de Jorge Luis Borges. Es una de sus piezas más conocidas, sumamente referenciada por la literatura y la academia y tal vez también por la cultura popular, como no es la excepción aquí, por más uso y abuso que se haga de varias buzzwords del mundo tecnológico.
Si el lector logró sobrevivir a la primera parte de este texto (el presente artículo, no el cuentazo de Borges), tal vez encuentre algo familiar: ¿podría ser el Quijote de Pierre Menard la salida de un modelo de lenguaje (ML)? ¿El ML capaz de generar un nuevo Quijote, o al menos una parte, igual al original?
Al revisar la obra del francés, es fácil detectar un particular interés en la gramática, la lógica booleana y el análisis sintáctico, todas herramientas útiles para un investigador en PLN. De hecho, entre su bibliografía se encuentra:
b) Una monografía sobre la posibilidad de construir un vocabulario poético de conceptos que no fueran sinónimos o perífrasis de los que informan el lenguaje común, “sino objetos ideales creados por una convención y esencialmente destinados a las necesidades poéticas” (Nîmes, 1901).
h) Los borradores de una monografía sobre la lógica simbólica de George Boole.
n) Un obstinado análisis de las “costumbres sintácticas” de Toulet (N.R.F., marzo de 1921). Menard —recuerdo— declaraba que censurar y alabar son operaciones sentimentales que nada tienen que ver con la crítica.
Pero tal vez su modelo era en realidad pésimo y sus críticos del área del PLN —tal vez más crueles que los del mundo literario— dirían que su modelo estaba sobreajustando, ya que un modelo sobreajusta cuando no es capaz de generalizar, cuando solo aprendió los datos con que se entrenó pero es completamente ignorante a la hora de interpretar o generar nuevos; es como ir a un examen habiendo estudiado todo de memoria y no ser capaz de responder una pregunta sobre un tema inesperado o apenas apartado del temario. Y no sería tan terrible para el pobre Menard que su modelo sobreajustara: suele pasar, más con las redes neuronales, que así como aprenden bien, también tienen particular inclinación a overfittear.
Volviendo al cuento, el narrador se explaya sobre cómo Menard se preparó para semejante tarea, o cómo pudo haber entrenado el modelo:
El método inicial que imaginó era relativamente sencillo. Conocer bien el español, recuperar la fe católica, guerrear contra los moros o contra el turco, olvidar la historia de Europa entre los años de 1602 y de 1918, ser Miguel de Cervantes. Pierre Menard estudió ese procedimiento (sé que logró un manejo bastante fiel del español del siglo XVII) pero lo descartó por fácil. ¡Más bien por imposible! dirá el lector. De acuerdo, pero la empresa era de antemano imposible y de todos los medios imposibles para llevarla a término, este era el menos interesante.
¿Estuvo en fase de entrenamiento inyectando a su modelo textos de la época de Cervantes? Agrega en carta el propio Pierre Menard sobre el proceso de escritura (¿o de entrenamiento?) de su Quijote, el Quijote:
Después, he releído con atención algunos capítulos, aquellos que no intentaré por ahora. He cursado asimismo los entremeses, las comedias, la Galatea, las Novelas ejemplares, los trabajos sin duda laboriosos de Persiles y Segismunda y el Viaje del Parnaso… Mi recuerdo general del Quijote, simplificado por el olvido y la indiferencia, puede muy bien equivaler a la imprecisa imagen anterior de un libro no escrito. Postulada esa imagen (que nadie en buena ley me puede negar) es indiscutible que mi problema es harto más difícil que el de Cervantes. Mi complaciente precursor no rehusó la colaboración del azar: iba componiendo la obra inmortal un poco à la diable, llevado por inercias del lenguaje y de la invención.
La queja del francés es evidente: el español era libre de escribir lo que quisiera, no tenía que replicar a nadie ni procesar texto para que una máquina lo entendiera, y menos a un autor de otra lengua que para colmo hace trescientos años era un tanto diferente.
Pero el esfuerzo de Menard dio sus frutos (al menos así lo pensaban algunos):
El texto de Cervantes y el de Menard son verbalmente idénticos, pero el segundo es casi infinitamente más rico. (Más ambiguo, dirán sus detractores; pero la ambigüedad es una riqueza.)
Los lectores de Menard, tal vez por puro esnobismo, sentían curiosidad y aprecio por un texto generado por una IA. Más sobre la tarea hercúlea del francés:
…empresa complejísima y de antemano fútil. Dedicó sus escrúpulos y vigilias a repetir en un idioma ajeno un libro preexistente. Multiplicó los borradores; corrigió tenazmente y desgarró miles de páginas manuscritas. No permitió que fueran examinadas por nadie y cuidó que no le sobrevivieran. En vano he procurado reconstruirlas.
El experto en PLN trabajando incansablemente en su modelo. ¡Cuántas versiones de su código habrá mandado a la papelera de reciclaje de su computadora! El cuento termina con un párrafo que parece ser una manifiesta defensa de las técnicas aplicadas por Pierre Menard:
Menard (acaso sin quererlo) ha enriquecido mediante una técnica nueva el arte detenido y rudimentario de la lectura: la técnica del anacronismo deliberado y de las atribuciones erróneas. Esa técnica de aplicación infinita nos insta a recorrer la Odisea como si fuera posterior a la Eneida y el libro Le jardin du Centaure de madame Henri Bachelier como si fuera de madame Henri Bachelier. Esa técnica puebla de aventura los libros más calmosos. Atribuir a Louis Ferdinand Céline o a James Joyce la Imitación de Cristo ¿no es una suficiente renovación de esos tenues avisos espirituales?
El trabajo de Menard tiene un fin absolutamente imitativo: busca replicar a la perfección una novela ya existente. Es, si se quiere, un tanto obsesivo, maníaco. ¿Pero qué pasa si el lector no quiere leer obras-réplicas, sino nuevas? ¿Si al lector no le interesa el desafío de la reproducción exacta sino la novedad? También al escritor-operador de máquinas generadoras de texto le podría seducir más la idea de producir piezas completamente nuevas e innovadoras.
Puede que una industria editorial donde los textos son producidos por modelos de lenguaje —o vaya a saber qué en un futuro— jamás prospere, que los lectores prefieran continuar leyendo a autores humanos, sin intermediarios. Pero también cabe la posibilidad de que una industria productora de textos de consumo masivo generados por máquinas no sea una locura. Una lógica de mercado llevada al paroxismo, con algoritmos que pueden predecir qué querrán leer las personas, los consumidores, no está tan alejada de otras estrategias de marketing ya utilizadas, aunque por ahora sea más bien en otros rubros, como el e-commerce. Los modelos computacionales podrán escribir obras customizadas a cada lector de acuerdo a toda la información recabada (cosa que ya hacen las redes sociales y demás plataformas): novelas hechas a medida del gusto y la moral de cada lector-consumidor. El crítico literario perdería sentido.
Cuando surgió la imprenta en el siglo XV, las clases productoras de conocimiento, principalmente conformadas por el alto clero, vieron al invento de Gutenberg como una amenaza: era perder el monopolio del conocimiento y el control de la información, o si eras un escriba, tu trabajo. Parecía una locura. Algunos predijeron su fracaso, su inviabilidad. Pero en cuestión de pocas décadas, un ritmo elevado para la época, se extendió por toda Europa, y con ella surgieron miles y miles de nuevos lectores que de otra forma no hubieran accedido a los libros.
Tal vez a quienes nos gusta leer nos parezca una locura, un sinsentido, pero quizá en un futuro la nueva literatura producida por inteligencias artificiales tenga atractivo para millones de personas. ¿No nos hubiera parecido ridículo que a fines los 90 alguien nos prometiera que en poco más de diez años íbamos a poder compartir una transmisión en vivo de nosotros mismos mediante una aplicación informática llamada Instagram con más de mil millones de usuarios?
Acompaña la entrada una fotografía del manuscrito del cuento de Borges, exhibido en Udolpho.

Deja un comentario